
一. 1.7原理简单概述
在java1.7中,ReentrantLock+Segment。其中 Segment 继承于 ReentrantLock。不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步(synchronized)处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
get方法
public V get(Object key) { Segment<K,V> s; // manually integrate access methods to reduce overhead HashEntry<K,V>[] tab; int h = hash(key); long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null && (tab = s.table) != null) { for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE); e != null; e = e.next) { K k; if ((k = e.key) == key || (e.hash == h && key.equals(k))) return e.value; } } return null; }a. 将key通过hash定位到segment
b. 再经过一次hash定位到真正的HashEntry数组中对应的位置。HashEntry结构如下所示
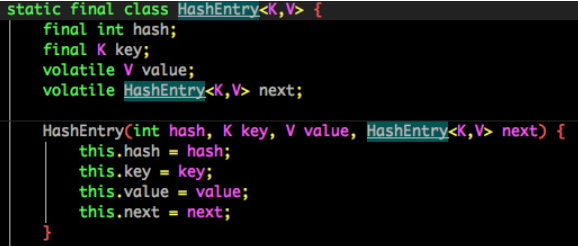
由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值。ConcurrentHashMap 的 get 方法是非常高效的,因为整个过程都不需要加锁。
put方法
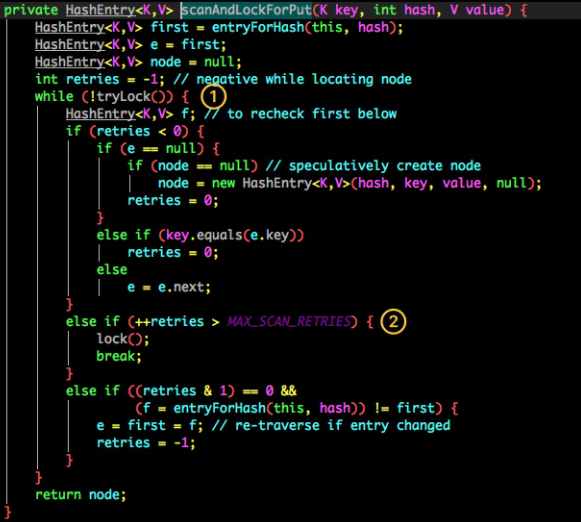
(1)处代码:尝试自旋获取锁。
(2)处代码:如果重试的次数达到了 MAX_SCAN_RETRIES 则改为阻塞锁获取,保证能获取成功。
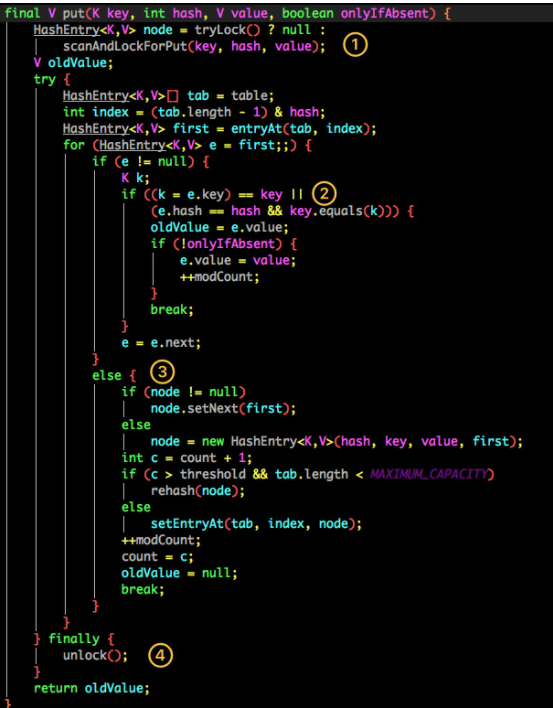
(1)处代码:将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry。
(2)处代码:遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value。
(3)处代码:为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容。
(4)处代码:最后会解除在 上面1 中所获取当前 Segment 的锁。
二. Java8实现
在Java8中是基于synchronized+CAS+红黑树进行实现的。但在JDK1.8中摒弃了Segment分段锁的数据结构,基于CAS操作保证数据的获取以及使用synchronized关键字对相应数据段加锁来实现线程安全,这进一步提高了并发性。
ConcurrentHashMap的节点
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; volatile V val; //使用了volatile属性 volatile Node<K,V> next; //使用了volatile属性 ... }ConcurrentHashMap采用Node类作为基本的存储单元,每个键值对(key-value)都存储在一个Node中,使用了volatile关键字修饰value和next,保证并发的可见性。其中Node子类有:
ForwardingNode:扩容节点,只是在扩容阶段使用的节点,主要作为一个标记,在处理并发时起着关键作用,有了ForwardingNodes,也是ConcurrentHashMap有了分段的特性,提高了并发效率
TreeBin:TreeNode的代理节点,用于维护TreeNodes,ConcurrentHashMap的红黑树存放的是TreeBin
TreeNode:用于树结构中,红黑树的节点(当链表长度大于8时转化为红黑树),此节点不能直接放入桶内,只能是作为红黑树的节点
ReservationNode:保留结点
put操作
final V putVal(K key, V value, boolean onlyIfAbsent) { // 1. 如果key或者value为null,则抛出空指针异常,和HashMap不同的是HashMap单线程是允许为Null if (key == null || value == null) throw new NullPointerException(); // 计算索引的第一步,传入键值的hash值 int hash = spread(key.hashCode()); // 保存当前节点的长度 int binCount = 0; // 2. // 如果table为null或者table的长度为0,则初始化table,调用initTable()方法(第一次put数据,调用默认参数实现,其中重 // 要的sizeCtl参数) for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; // 如果table为null或者table的长度为0 if (tab == null || (n = tab.length) == 0) // 初始化Hash表 tab = initTable(); // 3. 通过tableAt()方法找到位置tab[i]的Node,当Node为null时证明数组这个位置还没有元素,使用casTabAt()方法CAS // 操作将元素插入到Hash表中,ConcurrentHashmap使用CAS无锁化操作,这样在高并发hash冲突低的情况下,性能良好。 // 通过tableAt()方法找到位置tab[i]的Node,当Node为null时证明数组这个位置还没有元素 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { // 使用casTabAt()方法CAS操作将元素插入到Hash表中,这里没法用synchronized,因为 // 是为null的。 if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } // 说明ConcurrentHashmap需要扩容 else if ((fh = f.hash) == MOVED) // 如果当前线程发现正在扩容,会去帮助扩容,而不是干等着 // 怎么帮?每个线程分配16个槽位给你 tab = helpTransfer(tab, f); // tab[i]不是null,发生了hash冲突,要看该插入到哪里去 else { V oldVal = null; // 锁住hash entry中的头结点即可 synchronized (f) { // 判断下有没有线程对数组进行了修改 if (tabAt(tab, i) == f) { // 如果hash值是大于等于0的说明是链表的情况 if (fh >= 0) { binCount = 1; for (Node<K,V> e = f;; ++binCount) { K ek; // 插入的元素键值的hash值有节点中元素的hash值相同,并且key也相 // 等替换当前元素的值 if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) // 替换当前元素的值 e.val = value; break; } Node<K,V> pred = e; // 如果循环到链表结尾还没发现,那么进行插入操作 if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } // 是红黑树的情况 else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) // 替换旧值 p.val = value; } } } } if (binCount != 0) { // 如果节点长度大于8,并且数组长度大于等于64转化为红黑树 if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } addCount(1L, binCount); return null; }get操作
public V get(Object key) { Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; int h = spread(key.hashCode()); if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) { if ((eh = e.hash) == h) { if ((ek = e.key) == key || (ek != null && key.equals(ek))) return e.val; } else if (eh < 0) return (p = e.find(h, key)) != null ? p.val : null; while ((e = e.next) != null) { if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) return e.val; } } return null; }- 根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
- 如果是红黑树那就按照树的方式获取值。
- 就不满足那就按照链表的方式遍历获取值。
put操作如何保证线程安全
- 第一次调用put,初始化时
private transient volatile int sizeCtl; // 第一次put,初始化数组 private final Node<K,V>[] initTable() { Node<K,V>[] tab; int sc; while ((tab = table) == null || tab.length == 0) { // 如果已经有别的线程在初始化了 if ((sc = sizeCtl) < 0) // 当前线程便放弃初始化操作,让出CPU使用权 Thread.yield(); // lost initialization race; just spin // 否则,将sizectl设置成-1,原子操作, 表示正在初始化,然后进行初始化相关操作 else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { ... } finally { // 初始化成功以后,将sizeCtl的值设置为当前的容量值 sizeCtl = sc; } break; } } return tab; }- 不存在hash冲突时
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //利用CAS操作将元素插入到Hash表中 if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value))) break; // no lock when adding to empty bin(插入null的节点,无需加锁) }存在hash冲突时
在存在hash冲突时,先把当前节点使用关键字
synchronized加锁,然后再使用tabAt()原子操作判断下有没有线程对数组进行了修改,最后再进行其他操作。
为什么要锁住更新操作的代码块
防止前后两个线程put的数据相互覆盖
文档信息
- 本文作者:tangyejun
- 本文链接:https://tyjwan.github.io/2022/05/13/java-concurrent-hashmap/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)